
Advanced, durable AI memory is quickly becoming the key differentiator for real‑world AI systems, and Cognee, LightRAG, Graphiti, and Mem0 represent four distinct philosophies for building it. The chart below shows that Cognee, LightRAG, and Graphiti cluster near the top on human‑like and DeepEval metrics, while Mem0 trades some raw correctness for strong personalization and simplicity.
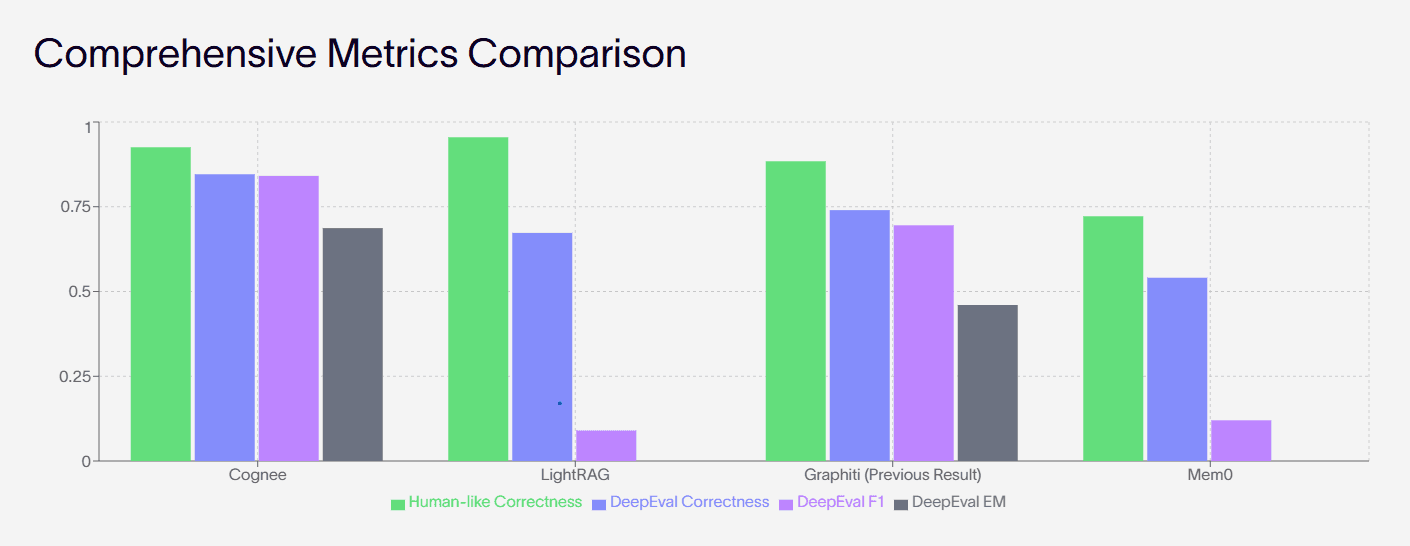
Source: https://www.cognee.ai/research-and-evaluation-results
Why Memory Is The Deciding Factor
Real‑world AI agents need to remember users, decisions, and evolving data, not just retrieve static chunks from a vector store. As systems scale from toy demos to copilots, agents, and workflows, three properties of memory dominate outcomes:
Temporal persistence: remembering how facts and relationships change over time.
Structural understanding: representing entities and relations instead of flat embeddings.
Personalization and safety: isolating users, enforcing boundaries, and surfacing only relevant context.
Cognee, LightRAG, Graphiti, and Mem0 all try to solve these problems, but with different trade‑offs in architecture, latency, and developer ergonomics.
Architectural Philosophies
System | Core paradigm | Storage model | Temporal handling | Personalization focus |
|---|---|---|---|---|
Cognee | Memory‑first graph RAG layer with evolving knowledge graph. | Unified graph + vectors over pluggable backends such as LanceDB and Redis. | Memify pipeline periodically cleans, reweights, and updates nodes and relations over time. | Workspaces and isolated memory per app or tenant; data can be kept local or hosted. |
LightRAG | High‑throughput RAG with graph‑augmented retrieval and flexible storage. | Separate KV, vector, graph, and doc‑status stores with many backends (Postgres, Neo4j, Milvus, Qdrant, Redis, Mongo, Faiss, etc.). | Supports incremental graph/index updates without full rebuilds to keep knowledge current. | Workspaces for data isolation across instances; tuned more for document‑centric workloads than per‑user profiles. |
Graphiti | Temporal knowledge graph engine designed as “real memory” for agents. | Neo4j‑style temporal KG with embeddings layered for hybrid search. | Bi‑temporal model (event time vs ingestion time) with validity intervals for each fact. | Namespaces and session‑aware storage to keep per‑user or per‑project memory separate. |
Mem0 | Universal long‑term memory layer for assistants and agents. | Hybrid of vector DB, key‑value store, and graph storage per memory. | Recency is part of its scoring layer, but it does not expose full temporal query semantics. | Strong emphasis on user‑, session‑, and agent‑level personalization with simple APIs and managed service. |
Cognee: Memory‑First Infrastructure
Cognee positions itself as a memory engine, not just another RAG toolkit, starting from an Extract–Cognify–Load pipeline that turns raw data into an evolving knowledge graph plus vectors. It ingests documents, APIs, and databases, extracts entities and relations, enriches them with temporal tags, and exposes a query layer that combines graph reasoning with vector search, which is where its high “human‑like” correctness scores in the chart come from.
For production agents, Cognee’s strengths are:
Durable infrastructure: it unifies graph and embeddings under one abstraction, so you do not have to orchestrate separate KG, vector DB, and doc store services yourself.
Self‑improving memory: the Memify step continuously cleans stale nodes and strengthens important edges, which helps keep accuracy close to 90% on knowledge‑heavy tasks.
Cognee is particularly attractive if the goal is to replace fragile RAG stacks with a single memory layer that can run locally in secure environments or scale via a managed platform.
LightRAG: Graph‑Augmented RAG at Scale
LightRAG is engineered for throughput and flexibility: it wraps a classic RAG pipeline with graph‑based entity‑relationship extraction while keeping each subsystem pluggable. Its architecture separates KV, vector, graph, and doc‑status storage, with adapters for Postgres, Redis, MongoDB, Neo4j, Milvus, Faiss, Qdrant, and others, making it easy to fit into existing infrastructure.
Key advantages in real‑world deployments:
Efficient incremental updates: LightRAG allows graph and index updates without rebuilding the entire store, reducing computational overhead and keeping responses aligned with fresh data.
Retrieval modes: local, global, hybrid, and mix modes let you bias toward entity‑level reasoning, chunk‑level retrieval, or both, which translates into the strong DeepEval correctness and F1 numbers in the chart.
LightRAG does expect powerful LLMs (32B+ parameters and long context) for best entity extraction, which may raise costs for some teams.
Graphiti: Temporal Knowledge as “Real Memory”
Graphiti starts from a different premise: real‑world memory is temporal and must keep track not only of what is true, but when it became true and when it stopped being valid. It stores interactions and facts in a temporal knowledge graph, tracking separate timelines for events and ingestion, so agents can query “what did we believe as of last quarter?” or “how has this entity changed over time?”.
Graphiti’s practical benefits include:
Persistent agent memory: its memory operator continually ingests conversations into the KG and automatically retrieves relevant past context by session or namespace.
Temporal conflict resolution: conflicting new facts are not just overwritten; they are marked with validity intervals so the system can preserve history while keeping current state consistent, which boosts long‑horizon correctness and EM scores.
Graphiti suits enterprise and analytics scenarios where decisions depend on how knowledge evolved—finance, compliance, patient histories, or multi‑month coding copilots.
Mem0: Personalization‑First Memory Layer
Mem0 focuses on being a drop‑in long‑term memory layer for assistants and multi‑agent systems rather than a full graph engine. When a message is added, Mem0 extracts user facts and preferences, then stores them across a vector database, key‑value store, and graph, and later surfaces the most relevant memories via a scoring function that balances relevance, importance, and recency.
Its main strengths:
Developer ergonomics: a simple add() / search() API, SDKs, and a managed service make it easy to bolt Mem0 onto chatbots, customer support, or productivity tools without deep infra work.
Multi‑level personalization: Mem0 explicitly models user, session, and agent memory, which drives high human‑perceived F1 on personalization‑heavy tasks despite lower EM on strict factual benchmarks in the chart.
Mem0 is ideal when the priority is quickly giving each user a persistent assistant that remembers their preferences and history, rather than deep graph reasoning over complex enterprise data.
Choosing the Right Memory Layer
From the metrics and architectures, the “best” choice depends on what “real‑world” means in a given product.
For knowledge‑heavy agents that must reason over complex, evolving datasets (docs, APIs, data warehouses), Cognee offers the most integrated memory‑first architecture and top‑tier correctness.
For teams that want maximal control over storage backends and need a fast, tunable RAG engine with graph awareness, LightRAG is the most modular option.
For applications where time and historical state are central—auditable agents, financial and medical systems—Graphiti’s temporal KG becomes the deciding factor.
For assistants and consumer or SaaS products where personalization and speed of integration matter most, Mem0 provides the simplest path to sticky long‑term AI memory.